Building a machine-learning pipeline with scikit-learn and Qt - Part V
In part IV some data preprocessing techniques were shown. After we have clean data, it is important to choose a set of features to use. This post presents an overview of some of the available methods that we can use.
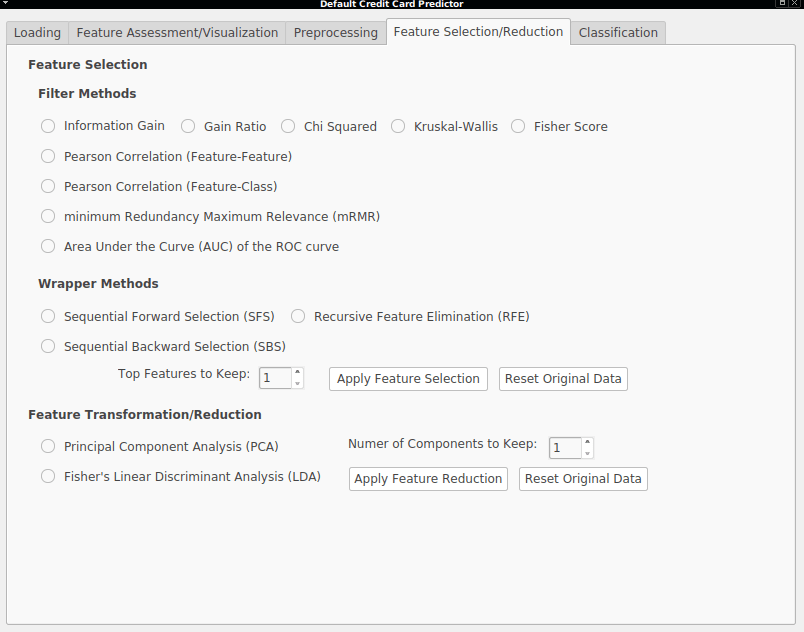
Feature Selection
Feature selection usually involves selecting a subset of the original set of features that provide the biggest discriminatory power, i.e., are able to provide the best separation between classes, result in the best performance of the classifier when trained and avoid the curse of dimensionality. In fact, it has been said that exists a critical feature dimension from where the performance degrades rapidly. Feature selection helps in removing irrelevant and redundant features and is usually divided into filter methods, where a subset of features is selected, without considering the predictive model and wrapper methods which use the classifier to rank and choose the best feature set. This step, in conjunction with feature reduction, is likely to be one of the most important steps in the pipeline. The following list shows common techniques employed in feature selection:
Information Gain - Information gain ranks each attribute by its ability to discriminate the pattern classes. Features very informative will provoke the greatest decrease in entropy when the dataset is split by that feature. \[ IG(S,A) = H(S) - { H(S) \over \sum { |S_v| \over |S|} H(S_v)} \] The Information Gain IG of a feature A is then equal to the decrease in entropy achieved by splitting the dataset S by feature values v into smaller sets Sv , and subtracting from the original entropy H(S) the average entropy of the splits.
Gain Ratio - The gain ratio is simply the information gain normalized with the entropy of the feature H(A). Since features with many values create lots of branches, creating a bias towards these features, the gain ratio corrects this by taking into account the number and size of branches of a split. \[ GR(S,A) = {IG(S,A) \over H(A) }\]
Fisher Score - The Fisher’s score select features with high class-separability and low class-variability and is defined by: \[ F(x) = {|m_1 - m_2|^2 \over s_1^2 + s_2^2 }\] where m1 and m2 are the means from the feature values (for a 2-class problem) and s1 and s2 are the standard deviations from the feature values of each class.
Pearson Correlation - Pearson correlation can be used to select features that are highly correlated with the target class and features with low correlation between them. It is a useful measure to see how strongly related two features are. The Pearson correlation gives values between -1 and 1, where absolute values closer to 1 mean a high correlation. The sign indicates whether there is a positive relationship between the variables, that is, if a feature value increase or decreases, the other increases/decreases as well (positive correlation) or if one variable increases/decreases, the other decreases/increases with it (negative correlation). Naturally, we are interested in high absolute values for feature-class relationships and low values for feature-feature relationships. This Pearson correlation ρ is defined as: \[ ρ(a,b) = {covariance(a,b) \over σ(a) \times σ(b) }\] where a and b can be both feature vectors or a feature vector and a label vector.
Chi-Square Test - The Chi-Square test ranks each attribute by computing the χ2 statistic relative to the target class. This statistic is useful to see if there is an independence relationship between the features and the target class. High values of this statistic means that there is a strong dependence between a particular feature and the target class leading to its selection for classification tasks.
Feature Reduction
Feature reduction is also an important step that helps further reducing the dimensionality of the problem, reduces the complexity of the problem and decreases the computational costs. In order to reduce the dimensionality, it is important to keep only the most relevant, informative and discriminative features. Techniques such as Principal Component Analysis (PCA) may be employed in this stage, by aggregating multiple features through linear combinations.
- Principal Component Analysis (PCA) - PCA is a popular unsupervised (ignores class labels) dimensionality reduction technique that uses linear transformations to find the directions (principal components) with the highest variance. It projects the original data into a lower dimensional space, with the new features retaining most of information. PCA works by finding vectors (called eigenvectors) with the highest amplitude (called eigenvalues) that represent the axes with the highest variance. The original data is then project onto these axes.
Successful removal of noisy and redundant data typically improves the overall classification accuracy of the resulting model, reducing also overfitting. After every preprocessing and feature engineering step is completed, comes the learning and evaluation phase which will be discussed in the next post.