Building a fast inference service with falcon and bjoern
A good portion of time in building supervised machine learning models is spent into training, that is, finding the best set of parameters that will give us the best accuracies on unseen data. Once we are satisfied with the obtained results, we often need to deploy and make it available to answer queries from a wide range of sources.
We can elaborate complex scenarios that are able to scale and answer to thousands of requests. However, let us consider that we need to prototype and showcase a quick solution, without sacrificing performance and scalability.
For this scenario we can combine the Falcon framework, which is a highly optimized and reliable web framework with bjoern, a very lightweight and fast WSGI server. This post shows a possible use of these tools. For the inference model, we will use a pre-trained model built with the fasttext classification tool. This model is able to classify text according to its polarity.
Installing dependencies
- Optional virtual environment
1 | virtualenv -p python3 venv |
- Falcon and Bjoern
1 | pip install ujson |
- FastText
1 | git clone https://github.com/facebookresearch/fastText.git |
Download the pre-trained model
1 | mkdir models |
Creating a REST resource
In order to serve requests by answering with polarity predictions (number of stars), let's define a resource by specifying a REST endpoint.
1 | import fastText |
In the above code, we define an handler for POST requests, instantiate the application, configure routing and finally run the bjoern WSGI server.
Making queries
The command bellow allow us to make queries to our web server. As an example, the request asks for a rating of the following review: 'I love this product.'
1 | curl -X POST http://localhost:9000/inferreview -H 'Content-Type: application/x-www-form-urlencoded' -d text="I love this product." |
which gives the desired classification, along with its confidence:
1 | { |
How does it scale ?
We have a server answering to client queries. We can make a quick test in order assess the scalability of our system. The wrk2 tool is perfect for this since it allows to record the latency distribution for different throughput (request per second) values.
1 | git clone https://github.com/giltene/wrk2.git |
The above command tests our server using 4 client threads, keeping 400 connections open, during 30 seconds and with a constant throughput of 20000 per second. The file scripts/post.lua is also modified as follows:
1 | wrk.method = "POST" |
The wrk2 tool generates a large output, containing a complete report with statistics in the HdrHistogram (High Dynamic Range Histogram) format, which we can use to make a plot of different throughput rates, as shown in the figure bellow:
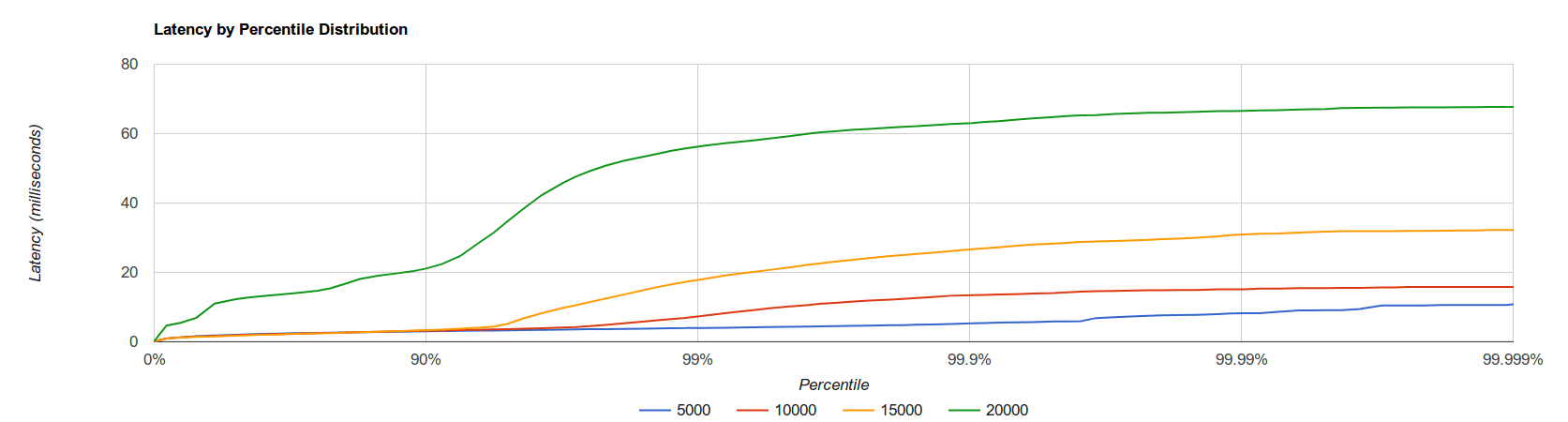
We can see the server handles 99% of all requests under 60 milliseconds, even when the throughput is 20000 requests per second, which is a fairly good performance. As a further comparison, the plot bellow shows a comparison with the popular wsgi server gunicorn, with the same constant throughput rate.
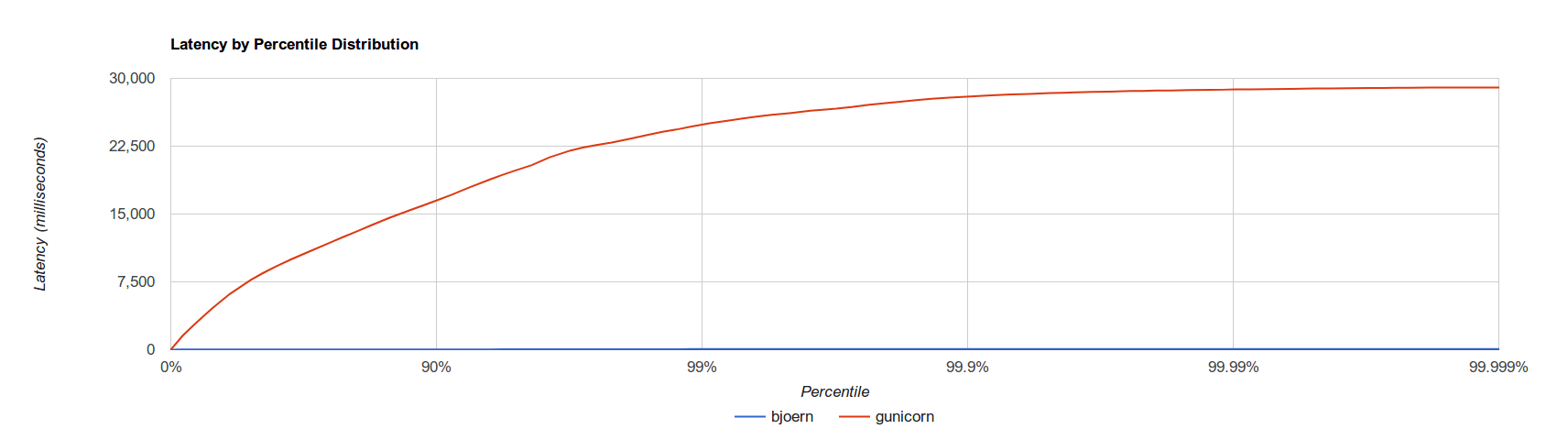
The gunicorn server ran with 9 asynchronous worker processes, based on gevent threads and it was called with the following command:
1 | gunicorn polarity_server:app -w 9 -k gevent |
It is clear that the bjoern server handled requests faster than gunicorn, and thus is a strong and faster alternative. These tests were performed on a standard laptop with 4 cores.
Final remarks
Falcon and Bjoern make a great combination to quickly serve thousands of requests with low effort and also make a good starting point for more complex scenarios. This speedup is justified since Falcon itself was compiled with Cython. We could have used the pypy python implementation alternative for even faster results. On the other hand, Bjoern is a very lightweight wsgi server, with a very low memory footprint, and single-threaded, which avoids locking overheads such as the GIL. The right combination of tools, allow us to worry less on performance issues and focus more on implementing the task that we want to provide. Finally, the source code is available here.