Building a machine-learning pipeline with scikit-learn and Qt - Part I
In machine learning problems, we usually describe the objects that we wish to recognize by a set of variables called features, consisting of information that we extract from the study objects. Such features are then collected in vectors of dimension d, called feature vectors, usually denoted by x. They represent points in a d dimensional space, called feature space. Each point belongs to a class, usually denoted by w and the combination of the feature vectors and their corresponding class are called patterns. If we only have two target classes, we are in the presence of a binary classification problem. Classification problems may be trivial for humans but are usually quite challenging for automated systems, since we need to deal with a lot of issues such as finding a reasonable number of distinguishing features good enough for classification, that are able to separate the target classes, or finding models that have good generalization capabilities (perform well on unseen data), avoiding overfitting of the model to the training data. The main goal is then to find the best decision boundary that results in the best generalization on testing data.
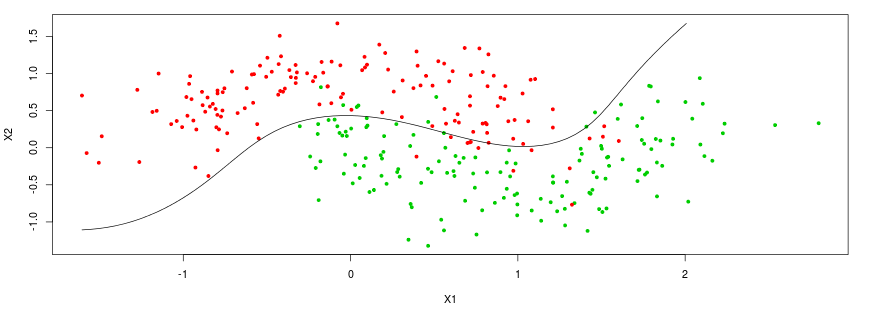
The figure below shows an hypothetical problem with two classes and two features. The main goal is then to find the best decision boundary that results in the best generalization on testing data.
The next figure shows the workflow of a typical machine learning application. Usually, classification involves steps such as data gathering, preprocessing, feature selection/reduction, training, testing and the final evaluation. The main goal is to assign, with the best accuracy possible, new labels to new instances.

In this post, we will see how we can recognize credit card frauds using classic algorithms. Default credit cards are an important issue that bring negative consequences to both sides, i.e, banks and customer. If a customer does not pay his obligations, banks loose money, the customer will lose credibility in future payments, collection calls start to be made and in last resort, the case may go into the court. In order to avoid all of that trouble, effective methods that are able to predict the default of credit cards are needed. Therefore, default credit card prediction is an important, challenging and useful task that should be addressed.
Python is a great choice for the development of this kind of applications, along with a series of helpful packages containing statistical and learning methods, namely the numpy and scipy packages for numerical computations, matplotlib , pandas and seaborn for data visualization, sklearn, mlxtend and unbalanced dataset for the learning and feature selection / reduction methods and finally the PyQt5 and Qt Designer for the Graphical User Interface (GUI).
Part II will look at the first step of the process: Data Gathering.